

“关于是否需要做预测的事情在上一篇文章《聊一下供应链需求预测》,已经很清楚的说明了是需要的,那么我们在日常的工作中如何去做呢?其实没那么高深,本文就说说利用excel做简单的需求预测。”
—— 供应链日常
所有预测都是错的,但准确度高和低还是不一样的
黄雪川,公众号:供应链日常聊一下供应链需求预测
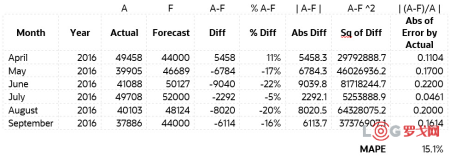
我们通常说的这个人靠不靠谱?是通过之前他说的和他做的是否一致来判断的。一个产品的预测是否靠谱,我们也可以通过看它的历史预测和实际生产/出货的差异来判断。在统计学中有这么一个衡量方法叫MAPE,平均绝对百分比误差(Mean Absolute Percentage Error)

MAPE取值的范围[0,+∞),MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型。注意:当真实值有数据等于0时,存在分母为0的问题,该公式不可用!我们看一个示例:这个产品从4月到9月的MAPE为15.1%,还算靠谱的预测,

回归分析(Regression):确定两种或两种以上变量间相关关系的一种统计分析方法。通过数据间相关性分析的研究,进一步建立自变量(i=1,2,3,…)与因变量Y之间的回归函数关系,即回归分析模型,从而预测数据的发展趋势。
来源:网络
说起预测分析,很多人会想到大数据、AI算法、Tableau、python等等,其实在真实的工作中没那么复杂,也用不到那么高大上的工具和方法哈,最基本的就是使用Excel数据分析工具中的回归分析就可以了。如何做呢?我们来看一个例子。

一条汽车生产线,共线生产两种车型A5和B7,有一种A5车型专用长周期物料,必须提前做预测。我们先看看历史数据:

我们利用前面4个月的实际生产数据来做多元线性回归分析,生产天数作为变量X1,全月总量作为X2,车型A5作为目标Y。我们来看看知道下月生产天数和总的预计产量的情况下,我们如何预测A5车型的量。回归分析后的结果如下:

几乎所有的回归模型的软件,最终都会给出参数的显著性检验,一般我们只需要理解:
回归统计表:Multiple R即相关系数R的值,大于0.8表示强正相关;R Square是R平方值,又叫判定系数、拟合优度,取值范围是[0,1]。R平方值越大,表示模型拟合得越好。一般>70%就算拟合得不错,60%以下的就需要修正模型。这个案例里R平方0.98,还算相当不错;Adjusted R是调整后的R方,这个值是用来修正因自变量个数增加而导致模型拟合效果过高的情况,多用于衡量多重线性回归。
方差分析:df是自由度,SS是平方和,MS是均方,F是F统计量,Significance F是回归方程总体的显著性检验,这是我们比较关注的,F检验主要是检验因变量与自变量之间的线性关系是否显著,用线性模型来描述他们之间的关系是否恰当,越小越显著。残差是实际值与预测值之间的差,残差图用于回归诊断,回归模型在理想条件下的残差图是服从正态分布的。
第三张表重点关注P-value,也就是P值,用来检验回归方程系数的显著性,又叫T检验,是在显著性水平α(常用取值0.01或0.05)下F的临界值,一般以此来衡量检验结果是否具有显著性,如果P值>0.05,则结果不具有显著的统计学意义,如果0.01<p值<0.05,则结果具有显著的统计学意义,如果p<=0.01,则结果具有极其显著的统计学意义。t检验是看某一个自变量对于因变量的线性显著性,如果该自变量不显著,则可以从模型中剔除。< p="">
第三张表第一列我们可以得到此例的回归模型方程(参数取1位小数):
Y= -213.1+61.5X1+0.6X2
我们就可以利用这个方程来预测一下5月的A5车型需求了,我们看看这个结果,可以看到还是比较准的:

既然所有预测都是错的,那么就一定有纠偏的过程。不管你用什么软件,最终的预测都不是100%准确的。对于这个偏差的态度,很大程度上决定了一家公司供应链协同的水平。比较常见的三种极端:
1.躺平:销售你说是多少就是多少,我也不做预测也不做考核,反正当二传手,销售报过来的数据就原封不动转给供应商,多了少了,都和我没关系;这样可是苦了很多供应商,一但出大问题其实你的交付也成问题,最终客户利用受损,公司也自然不要想赚钱了;
2.内卷:对销售的预测数据做KPI考核,非得想办法搞得你难受,反正预测不准我难受了,你也不得好受。但大家都知道,很多事情一旦考核就会造成人们行为变形。为提高预测准确性,时间越靠近就越准,销售通常会拖到最后时刻才给数据,这对较长的供应链也是没有好处的。预测准了,物料还是供应不上;
3.摆烂:老子就是硬,不管你什么销售预测,我说是多少就是多少,多了我没有,少了你也得接受。谁叫你预测不准呢?
看了上面几条估计有人都在乐了,在现实生产中这样的狗血事件太多了。其实都不好,我们要"看清生活的真相,还依然热爱生活",这才是我们对待预测的正确态度,物料需要有基本的预测,同时需要同上下游基于基本预测做真诚沟通,不断去修正我们的预测。
比如前面我举例的A5车型预测,这个结果是在正常情况下的预测,但如果某月出现过一些疫情、促销、新品上市等情况时候,这个模型计算出来的数据就不对了。这个时候可能需要采用多元非线性预测模型了,而这些"事件"不是物料计划能预测或第一时间知道的,需要别的部门通知和多部门判断。这个过程就是一个协同和管理的过程,你说它是不是体现了一个公司的供应链协同水平?


途虎养车2025年中城配线路运输招标-报名公告
3245 阅读
年赚50亿元的物流企业都有哪些?
1235 阅读
新产业、新客群、新场景:顺丰控股“激活经营”3月营收236.61亿元,速运业务量超行业增长达25.36%
926 阅读中美航线大量货轮停航
857 阅读美国4月1日至8日进口订单大降64%!
700 阅读美团即时零售品牌“美团闪购”即将发布
729 阅读拼多多“千亿扶持”加速电商西进,商家争相掘金西部大市场
672 阅读顺丰亮相第137届广交会 “智链全球”助力中国企业全球化布局
680 阅读抖音电商下线“音需达”送货上门服务
660 阅读中国石化宣布我国首条跨区域氢能重卡干线正式贯通
676 阅读







粤公网安备 44030402005698号


 [罗戈导读]利用excel做简单的需求预测
[罗戈导读]利用excel做简单的需求预测

_SSw1rTPJ7WAQ.jpg?x-oss-process=image/quality,Q_80/watermark,t_80,g_se,x_10,y_10,image_aURxY29TdHhRb0RzLnBuZz94LW9zcy1wcm9jZXNzPWltYWdlL3Jlc2l6ZSxQXzIw)











